Просмотр результатов узла Адаптивный бустинг
Окно просмотра результатов узла Адаптивный бустинг включает следующие вкладки: Параметры модели, Дерево, Эффективность классификации, Детали классификации, Матрица ошибок, Метрики классификации, ROC-анализ, Точность-Полнота, Gain-кривая, Lift-анализ, Важность признака и Настройки.
Вкладка Параметры модели

Вкладка Параметры модели содержит фактическое число шагов бустинга (оно может быть ниже чем число шагов бустинга, указанное в настройках узла.
Вкладка Дерево

Вкладка Дерево отображает интерактивное решающее дерево, построенное на первом шаге бустинга. Если данные расщеплялись для обработки на нескольких компьютерах, то это дерево показывается полностью с корневым расщеплением, распределяющим данные по разным компьютерам. Таким образом, мы видим оказывается корневое расщепление, каждая ветвь которого продолжается первым решающим деревом бустинга, построенного на соответствующем компьютере.
Вкладка Эффективность классификации
Вкладка Эффективность классификации отображает основные статистические данные об эффективности классификации:

-
Точность классификации - показывает процент правильных классификаций в общем количестве записей;
-
Ошибка классификации – показывает процент неправильных классификаций в общем количестве записей;
-
Эффективность классификации – показывает, сколько раз (в процентах) алгоритм успешно выполнил классификацию.
Вкладка Детали классификации
Вкладка Детали классификации отображает альтернативную форму матрицы ошибок:
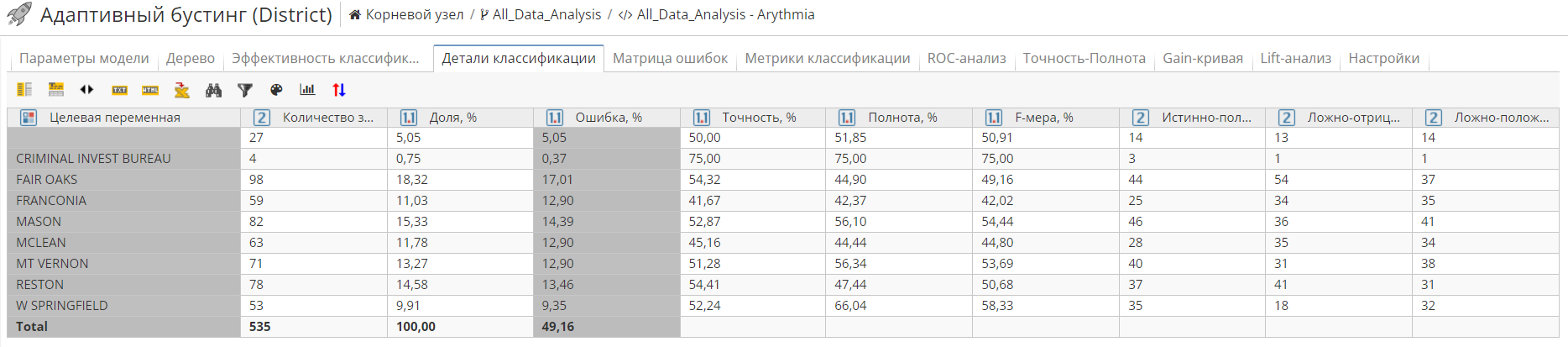
В ней приведена таблица уникальных значений целевой колонки и информация о точности для каждого целевого значения:
-
Целевая переменная – значение выбранной целевой колонки;
-
Количество записей – число записей (поддержка) во входных данных, содержащих указанное значение;
-
Доля – процентное соотношение записей во входных данных, содержащих указанное значение;
-
Ошибка - доля неправильной классификации в общем числе записей;
-
Точность – доля релевантных последовательностей среди обнаруженных последовательностей;
-
Полнота – доля обнаруженных релевантных последовательностей;
-
F-мера – мера точности, заимствованная из точности и полноты алгоритма;
-
Ложноотрицательные – процент ложноотрицательных результатов;
-
Ложноположительные – процент ложноположительных результатов.
Вкладка Матрица ошибок
Вкладка Матрица ошибок показывает матрицу ошибок:
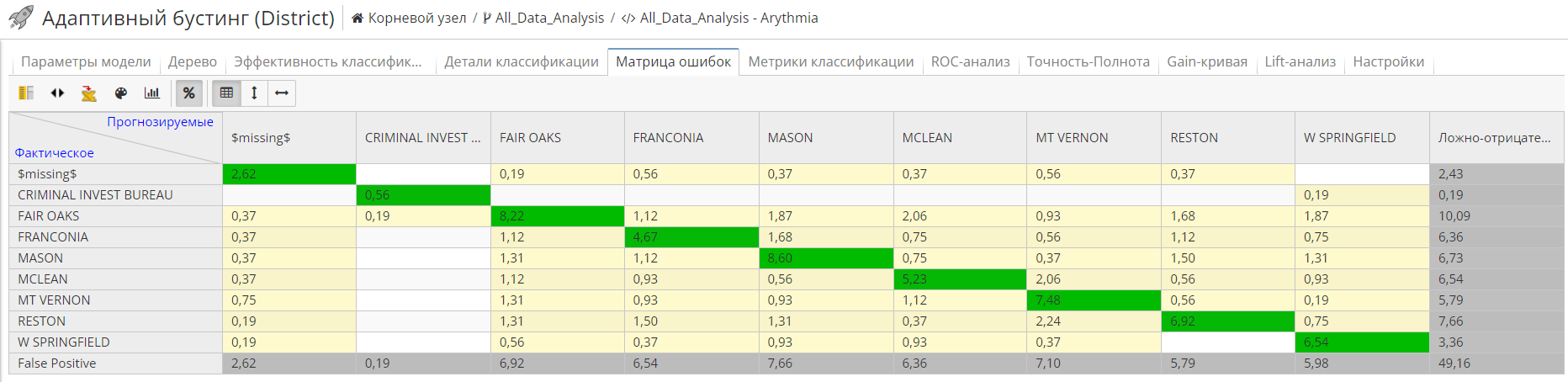
Матрица ошибок отображает коэффициент ошибки классификации для каждого класса (каждого уникального значения) целевой переменной. В колонках представлено прогнозируемое значение, а в строках – действительное. Диагональ матрицы представляет частоту правильной классификации.
Каждая ячейка представляет собой число долей соответствующего класса. Последняя строка и колонка показывают общую сумму ошибок в колонках и строках соответственно (т.е. без учета случаев корректной классификации). Эти общие суммы обладают тем же значением, что и ложноположительные и ложноотрицательные на предыдущей вкладке, но вычисляются в абсолютных значениях без отношения к категориям.
Вкладка Метрики классификации
Вкладка Метрики классификации показывает критерии для оценки качества моделей классификации, которые определяют насколько хорошо модель справляется со своей задачей:

-
Уточнение - доля правильных предсказаний (как положительных, так и отрицательных) среди всех предсказаний. Значение вычисляется как сумма истинно положительных (TP) и истинно отрицательных (TN) значений, деленная на общее количество валидных записей в используемом наборе данных:
(TP+TN)/(total predictions). -
Точность - доля правильных предсказаний (как для положительных, так и для отрицательных классов) среди случаев, которые были классифицированы как положительные. Значение вычисляется как число истинно положительных значений (TP), деленное на сумму истинно положительных значений (TP) и ложноположительных значений (FP):
TP/(TP+FP). -
Полнота - доля истинно положительных предсказаний среди всех реальных положительных классов. Значение вычисляется как число истинно положительных значений (TP), деленное на сумму истинно положительных значений (TP) и ложноотрицательных значений (FN):
TP/(TP+FN). -
Специфичность - доля истинно отрицательных предсказаний среди всех реальных отрицательных классов. Значение вычисляется как число истинно отрицательных значений (TN), деленное на сумму истинно отрицательных значений (TN) и ложноотрицательных значений (FP):
(TN)/(TN+FP). -
F-мера - гармоническое среднее между точностью и полнотой. Значение вычисляется как Точность, умноженная на Полноту, умноженная на 2 и разделенное на сумму значений Точности и Полноты:
(2*TP)/(2*TP+FP+FN). -
P4 - расширение F1-меры, обладающее симметрией относительно инверсии классов. Рассчитывается следующим образом:
(4*TP*TN)/(4*TP*TN+(TP+TN)*(FP+FN)). Диапазон значений от 0 до 1: чем ближе значение метрики к 1, тем лучше работает модель. -
Площадь под ROC-кривой (Receiver Operating Characteristic Curve) часто обозначают как AUC (Area Under Curve). Этот показатель оценивает способность модели различать между положительными и отрицательными значениями. Кривая ROC отображает отношение между показателем истинно положительных ответов и ложноположительных ответов при различных пороговых значениях классификации и рассчитывается по формуле:
2*auc-1. Чем выше значение AUC, тем лучше модель способна различать. Для не бинарной модели AUC-ROC считается по усредненной кривой. -
Джини представляет собой среднеквадратичный отступ от линии идеального равенства (или же случайного распределения), вычисляется по формуле:
\(Gini_{normalized} = \frac{Gini_{model}}{Gini_{perfect}} = 2 \cdot AUCROC - 1\)
Максимальный коэффициент Джини для текущего набора данных достигается идеальным алгоритмом и зависит только от истинного распределения классов: при равномерном распределении он равен 0.25. Форма фигуры для идеального алгоритма, образуемой Lift Curve и линией абсолютного равенства, всегда будет треугольником. Площадь фигуры для идеального алгоритма равна:
\(S = \frac{Число\enspace объектов\enspace класса\enspace 0\enspace в \enspaceвыборке}{2}\)
Коэффициент Джини случайного алгоритма равен 0, а его Lift Curve совпадает с линией абсолютного равенства. Коэффициент Джини обученного алгоритма всегда ниже идеального, и его нормализованные значения находятся в диапазоне [0, 1], где нормализованный коэффициент Джини максимизируется как метрика качества.
Обратите внимание, что все метрики для расчёта которых используются ложноотрицательные значения не могут быть вычислены для небинарных моделей.
Вкладка ROC-анализ
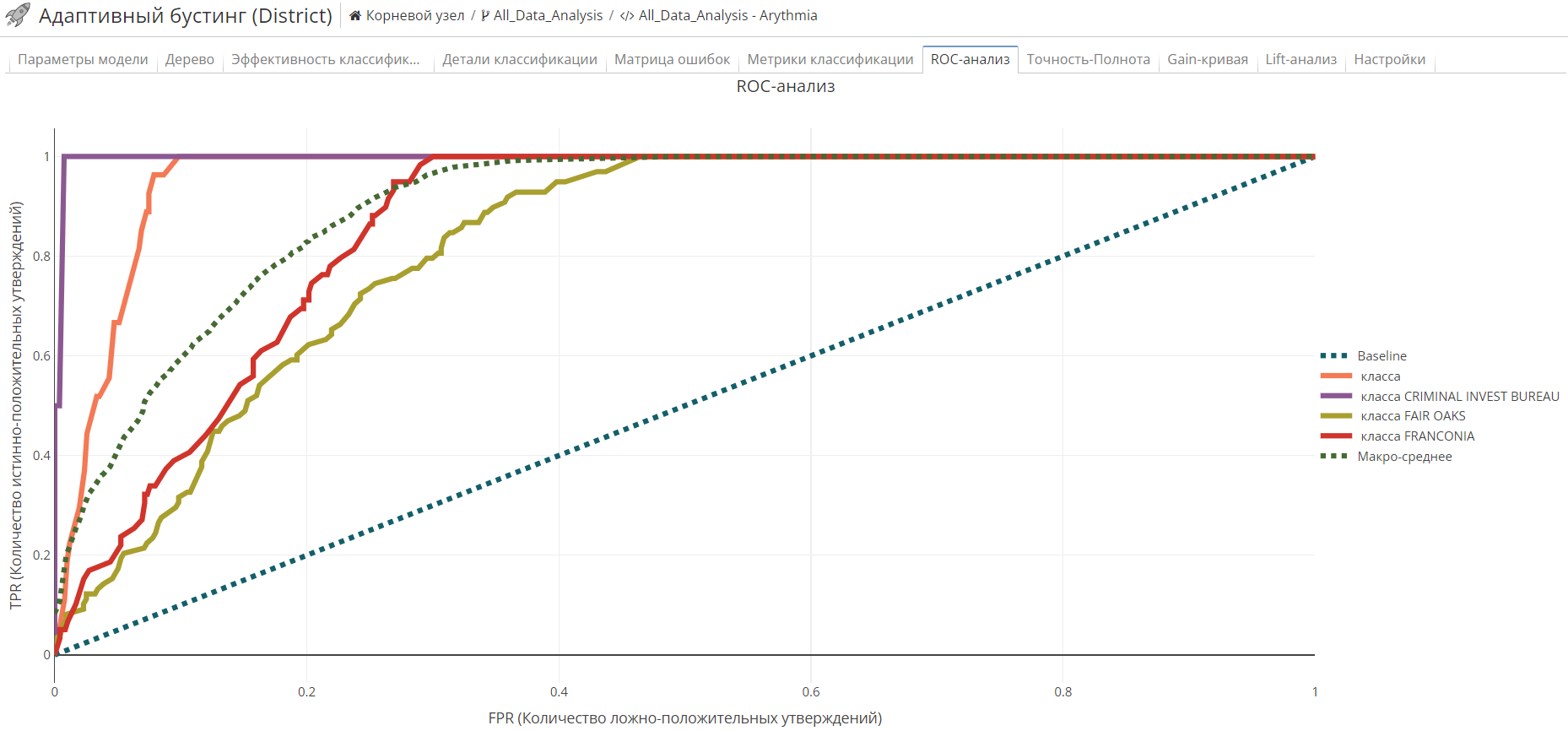
Вкладка ROC-анализ отображает ROC-график (соотношение чувствительности и 1-специфичности) и таблицу со следующими колонками. ROC-график показывает качество выбранной модели в соответствии с порогами классификации.
Вкладка Точность-Полнота
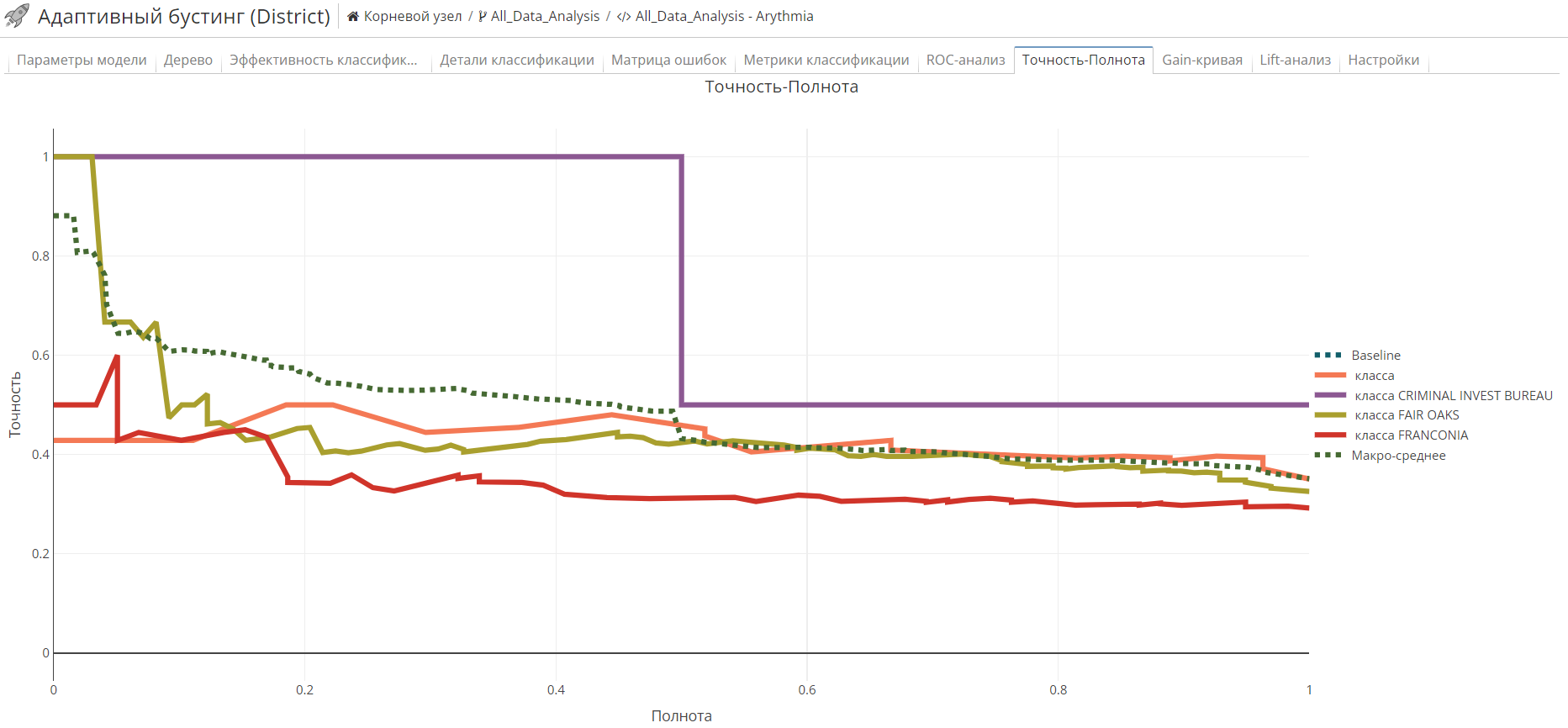
Вкладка Точность-Полнота отображает кривую Точности-Полноты, который представляет собой график со значениями Точности на оси y и со значениями Полноты на оси x.
Желательно, чтобы алгоритм характеризовался и высокой точностью, и высокой полнотой. Однако, большинство алгоритмов машинного обучения предлагают компромисс между этими двумя параметрами. Хороший результат на кривой Точности-Полноты обозначается большей площадью под кривой (AUC).
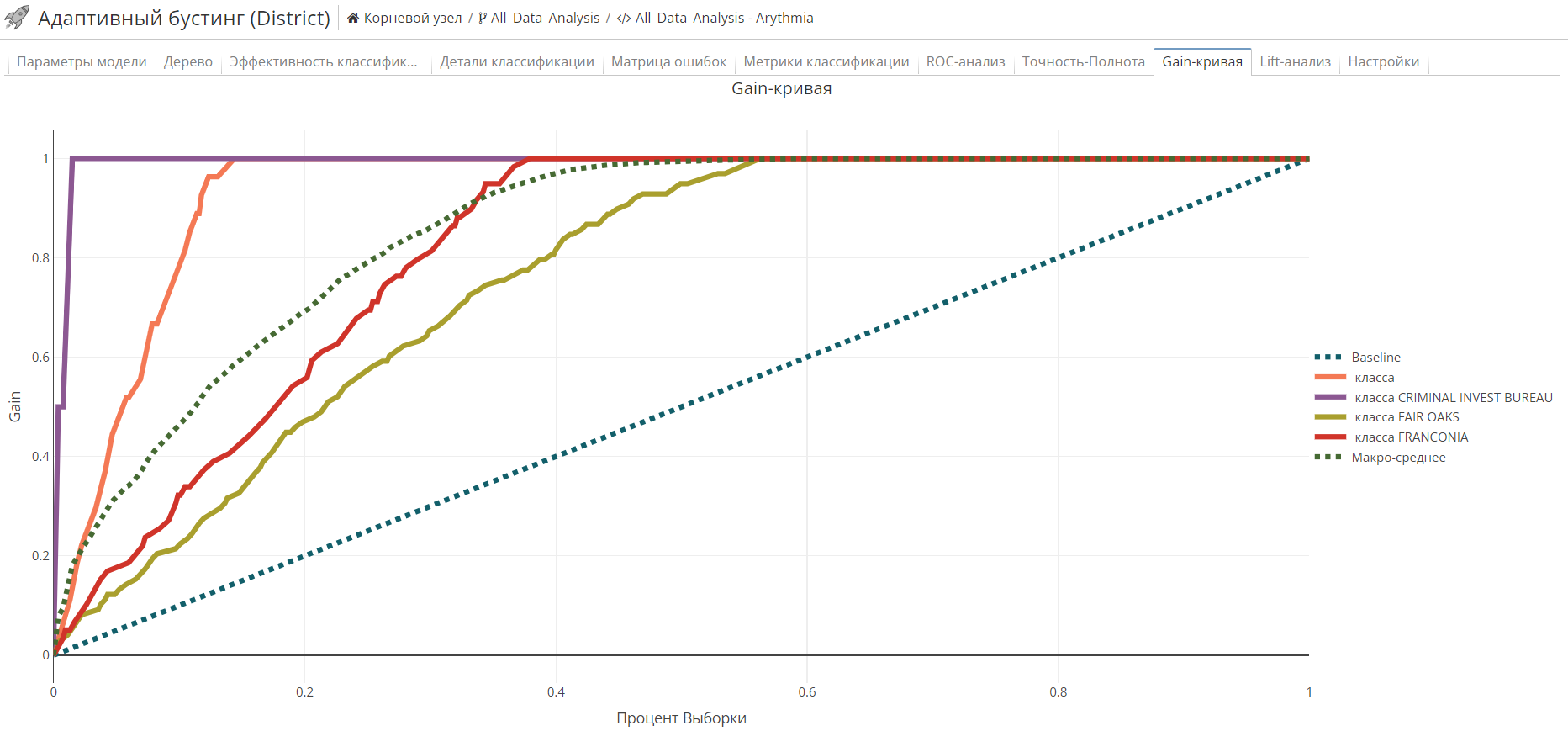
Вкладка Lift-анализ
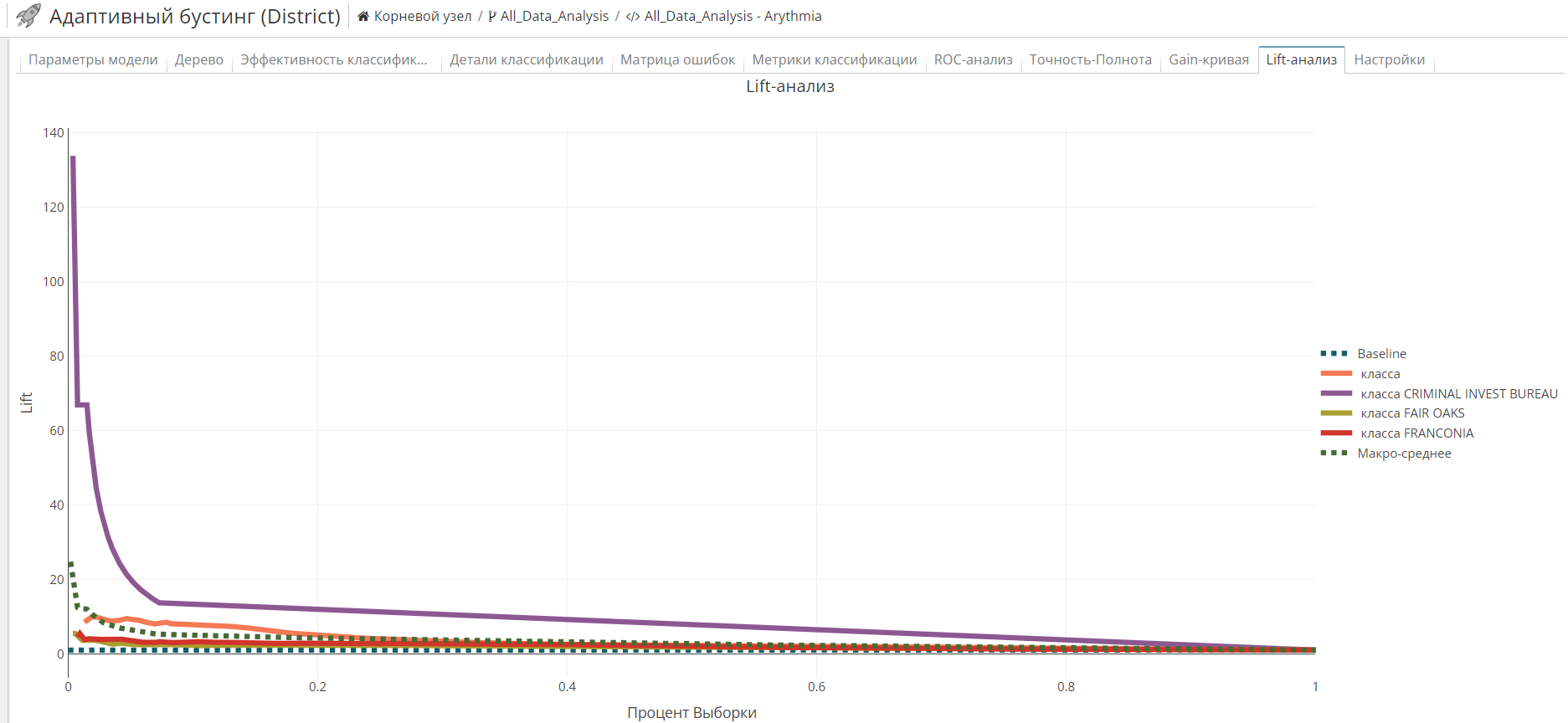
Gain и Lift - метрики адаптивного бустинга, помогающие понять преимущества используемой модели. Они рассчитываются следующим образом:
Gain |
Lift |
Прогнозируется вероятность Y = 1 (положительная) с использованием модели адаптивного бустинга и организуется наблюдение в нисходящем порядке прогнозируемой вероятности (т.е. P(Y = 1)). |
|
Данные делятся на децили. Рассчитывается число положительных значений (Y = 1) в каждом дециле и совокупное число положительных значений до дециля. |
|
Gain - отношение между совокупным числом положительных наблюдений до дециля и общим числом положительных наблюдений в данных. |
Lift - отношение между числом положительных наблюдений до дециля i с использованием модели и ожидаемым числом положительных значений до дециля i на основе случайной модели. |
\(\text{Gain}=\frac{\text{Совокупное число положительных наблюдений до дециля}}{\text{Общее число положительных наблюдений в данных}}\) |
\(\text{Lift}=\frac{\text{Совокупное число положительных наблюдений до дециля i с использованием модели машинного обучения}}{\text{Совокупное число положительных наблюдений до дециля i с использованием случайной модели}}\) |
Gain-кривая - это график, на вертикальной оси которого находится gain, а на горизонтальной - дециль. |
Lift-кривая - это график, на вертикальной оси которого находится lift, а на горизонтальной - соответствующий дециль. |
Оба графика включают минимум два элемента: Gain/Lift-кривая и Исходные данные. Чем больше площадь Gain/Lift-кривой и Исходными данными, тем выше качество модели.
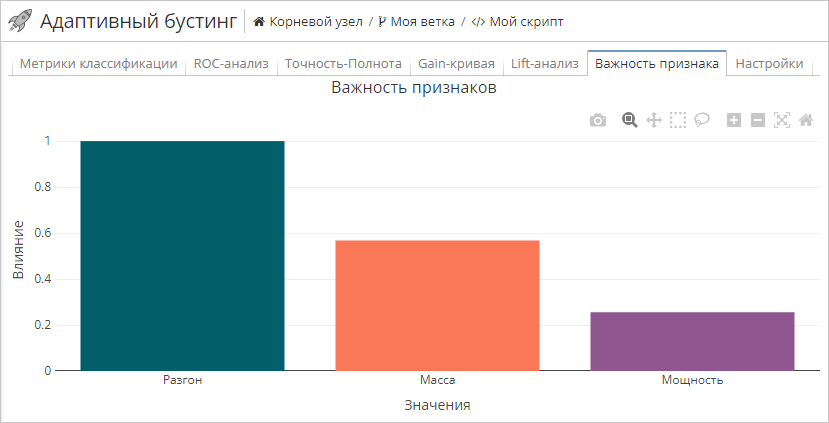
Вкладка Важность признака
При включении режима Рассчитать важность признака в окне настройки свойств узла Адаптивный бустинг его отчет будет включать дополнительный раздел – Важность признака. Данная вкладка содержит график, который отражает значимость выбранных независимых переменных:
В правом верхнем углу области графика располагается панель инструментов, которая предоставляет доступ к следующим функциональным возможностям:
-
 – сохранить текущий вид графика в PNG-файл.
– сохранить текущий вид графика в PNG-файл. -
 – увеличить выбранную область графика. Определение области для более детального изучения осуществляется путем нажатия на график и перемещения по нему курсора.
– увеличить выбранную область графика. Определение области для более детального изучения осуществляется путем нажатия на график и перемещения по нему курсора. -
 – перемещайтесь по графику, перетаскивая его в соответствующем направлении.
– перемещайтесь по графику, перетаскивая его в соответствующем направлении. -
 – используйте инструмент выделения в форме прямоугольника для выбора объектов на графике.
– используйте инструмент выделения в форме прямоугольника для выбора объектов на графике. -
 – используйте инструмент выделения в виде лассо для выбора объектов на графике.
– используйте инструмент выделения в виде лассо для выбора объектов на графике. -
 – увеличение масштаба на графике.
– увеличение масштаба на графике. -
 – уменьшение масштаба на графике.
– уменьшение масштаба на графике. -
 – выполнить автоматическую настройку размера графика.
– выполнить автоматическую настройку размера графика. -
 – восстановить исходный вид графика.
– восстановить исходный вид графика.